
Connais-tu Perplexity AI ?
Grâce à l’IA, ce moteur de recherche conversationnel synthétise les informations de multiples sources du web pour offrir la meilleure réponse à l’utilisateur.
Si tu découvres, tu peux essayer ici : https://www.perplexity.ai/
Dans cet article, tu vas découvrir une une app type Perplexity que j’ai réalisée avec Streamlit et n8n. Tu trouveras les fichiers sur mon github si tu veux essayer.
Tout au long de la lecture, tu peux cliquer sur les images pour les agrandir !
Pourquoi essayer de refaire Perplexity en no-code / low-code ?
Parce que c’est amusant 🙂.
Et plus sérieusement, parce que qu’extraire des informations du web de manière structurée et les exploiter avec un LLM pour générer une réponse synthétisée ou une analyse ouvre la porte à une multitude de possibilités !
Les services & API utilisées
- n8n, pour le workflow
- Streamlit, pour l’interface
- SerpApi, pour récupérer les résultats des moteurs de recherche
- JinaAI, pour obtenir le contenu des différentes sources dans un format LLM-friendly (en Markdown)
- OpenAI, pour les LLM, l’extraction d’information parmi les sources et la synthétisation de la réponse
Et pourquoi pas utiliser l’API de Perplexity directement ?
Parce que c’est moins amusant 🤓.
Et plus sérieusement car ça ouvre de la flexibilité sur :
- les modèles (même si plusieurs sont disponibles avec Perplexity),
- le nombre de résultats/sources analysées,
- les moteurs de recherche.
C’est aussi plus intéressant pour du test & learn par rapport à l’utilisation d’une API déjà existante.
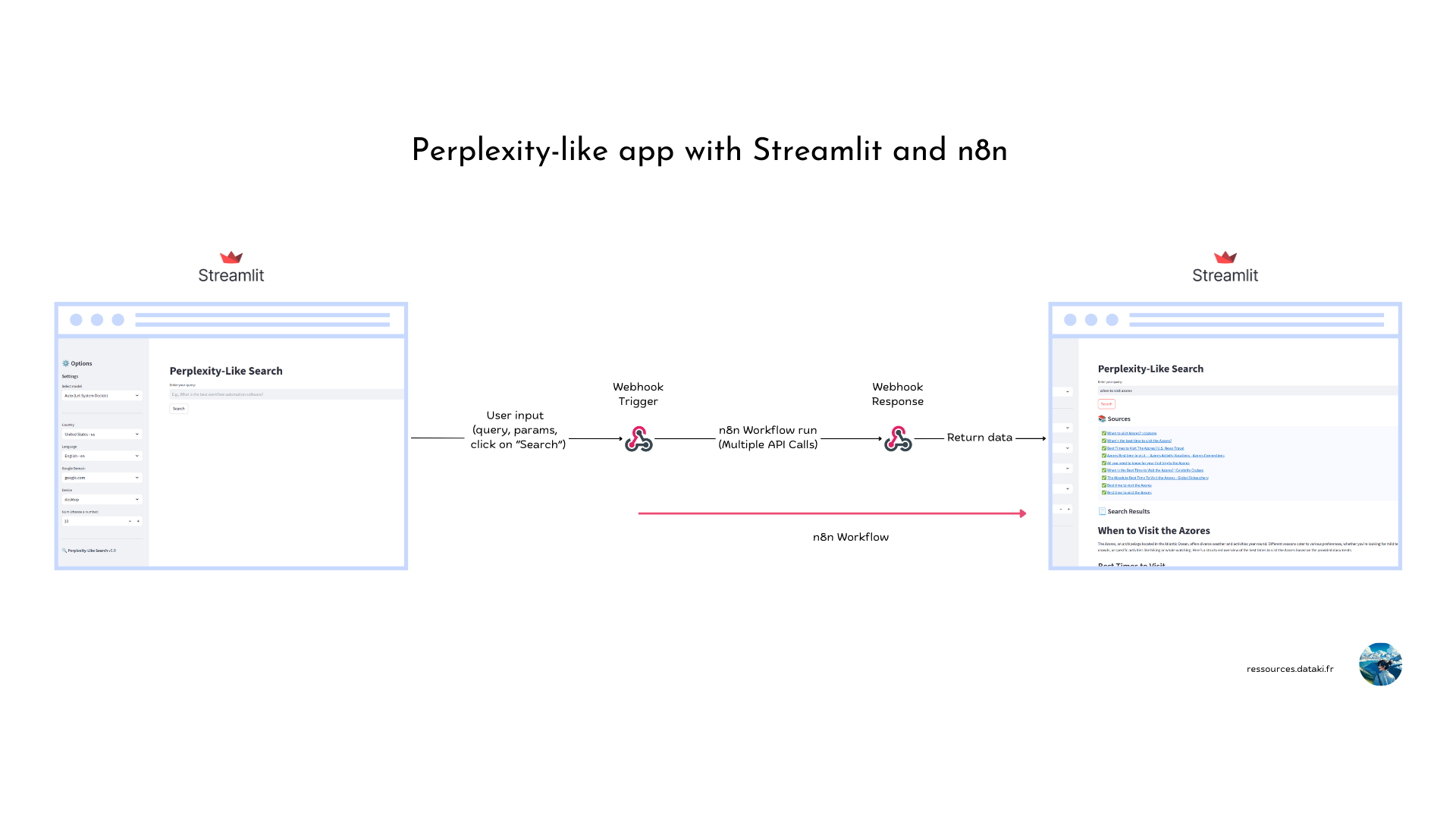
L’approche n8n + Streamlit
Streamlit est un framework Python pour déployer des app data/IA.
Il est facile à prendre en main, mais lorsque les logiques conditionnelles et appels API se multiplient, ça peut devenir complexe, pour un profil « bricoleur Python » (ce que je suis).
C’est pour ça que le backend est un workflow n8n.
Le fonctionnement est simple :
Lorsque l’utilisateur clique sur « Search« , la requête et les paramètres de l ‘utilisateur sont envoyés vers un webhook qui démarre le workflow n8n.
Puis, la réponse est retournée au webhook et affichée.
Grâce au format Markdown, la réponse est optimisée pour le lecteur (titre, tableaux, mots en gras, liens et même blocs de code si nécessaire).
SerpApi – L’API pour récupérer les pages de résultats de moteurs de recherche
SerpApi est un service très populaire pour récupérer les pages de résultats de moteurs de recherche (SERP).
Les SERP de Google, Bing, Yahoo (et bien plus) peuvent être récupérées.
Selon le moteur de recherche, l’appel API peut être configuré avec la localisation, langue des résultats, nombre de résultats retournés…
Pour notre Perplexity-like app, nous n’utiliserons cette API qu’avec le moteur de recherche Google. Donc les sources utilisées pour répondre aux recherches sur l’app, proviennent des résultats Google.
Jina AI – L’API pour récupérer le contenu d’une URL dans un format LLM-friendly
Jina AI est une entreprise qui fournit des services d’intelligence artificielle pour la recherche et l’accès à l’information.
Celui qui nous intéresse « Reader API » permet d’obtenir le contenu d’une URL dans un format LLM-friendly (en Markdown).
Pour mieux comprendre, tu peux essayer de récupérer le contenu d’un tutoriel de dataki ressources, en cliquant sur le lien ci-dessous :
https://r.jina.ai/https://ressources.dataki.fr/tutoriel/premier-agent-ia-assistant-google-calendar/
Tu verras une page texte s’afficher, avec des caractères spéciaux. C’est le format Markdown ! Facile pour le LLM de comprendre les titres, liens, mots en gras… et ça tient en moins de token que la version HTML.
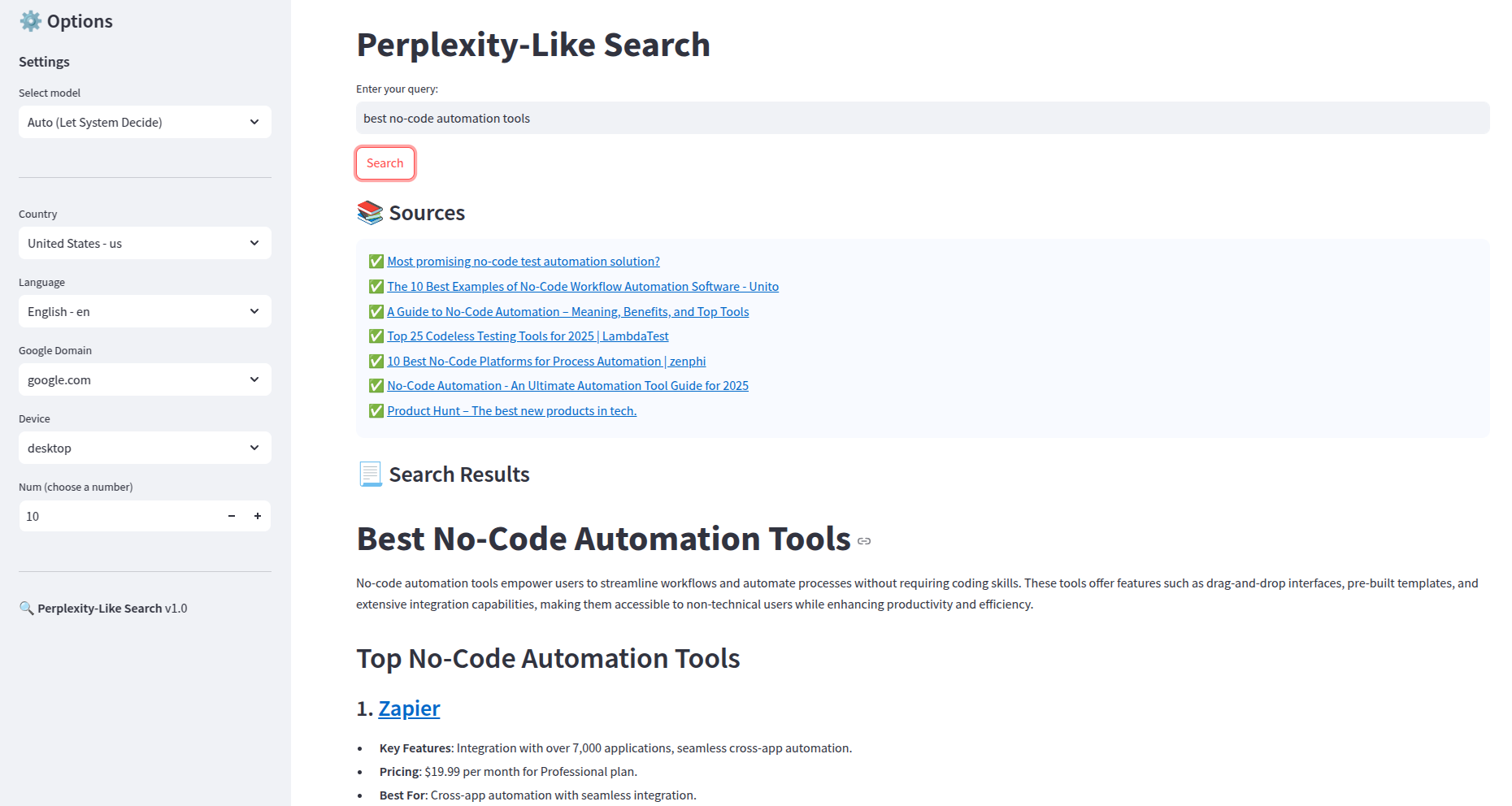
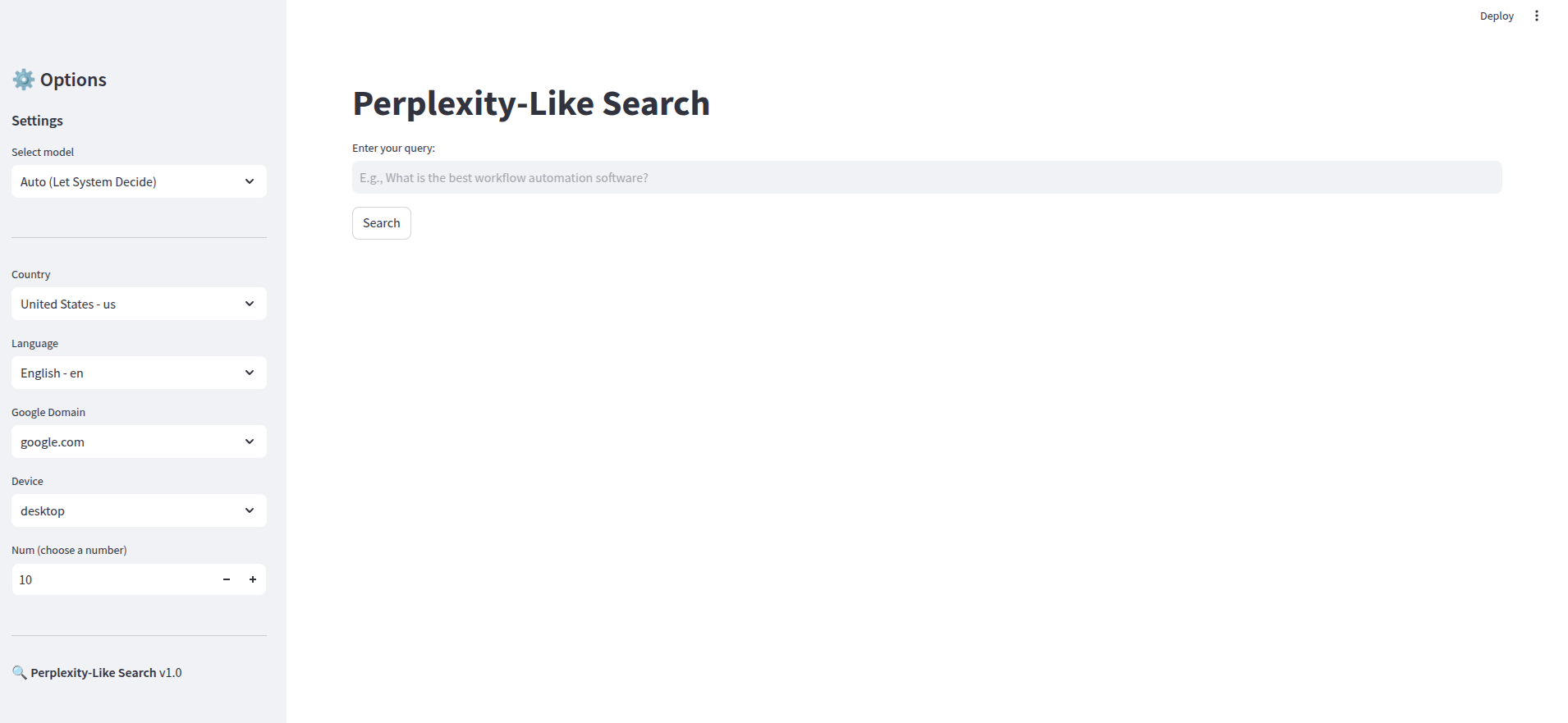
Le « frontend » : Une app Streamlit codée par OpenAI o1
Des LLM optimisés pour développer du code sont disponibles, alors autant les utiliser !
Avec un prompt demandant au modèle o1 de générer une app Streamlit avec :
- une barre de recherche
- une sidebar avec des options : choix du modèle, localisation de la recherche, langue de la recherche, domaine google utilisé, appareil (peu utile ici), nombre de résultats
- une requête POST vers un webhook lorsque l’utilisateur clique sur Search
- une barre de chargement
- un affichage structuré pour la réponse, profitant du format Markdown, et mettant en avant les sources
On a l’app ci-dessous :
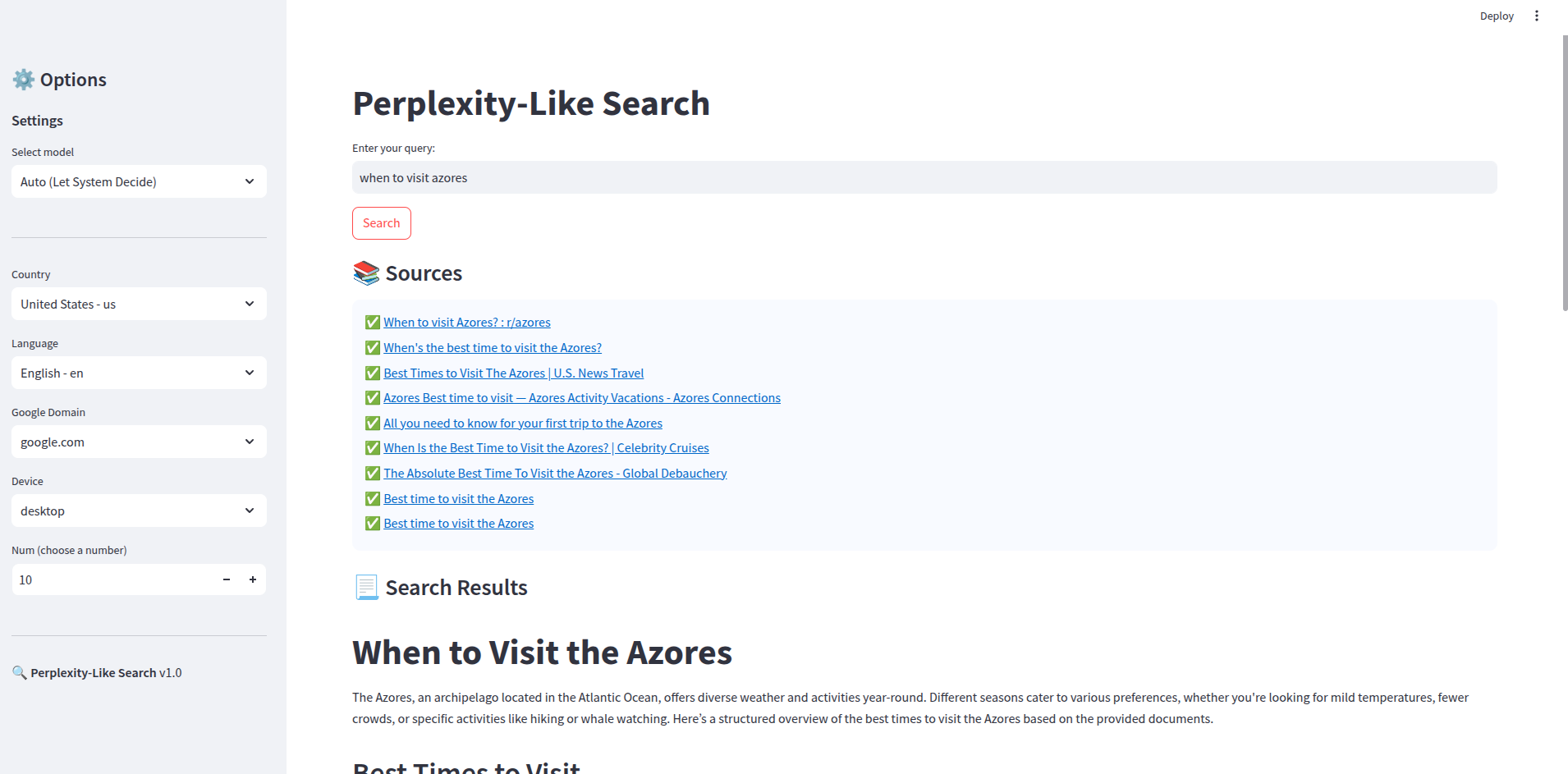
Entre les deux images il y a quelque chose : Le workflow n8n !
Le « backend » – Un workflow n8n en seulement 12 nodes (et 3 sub-nodes)
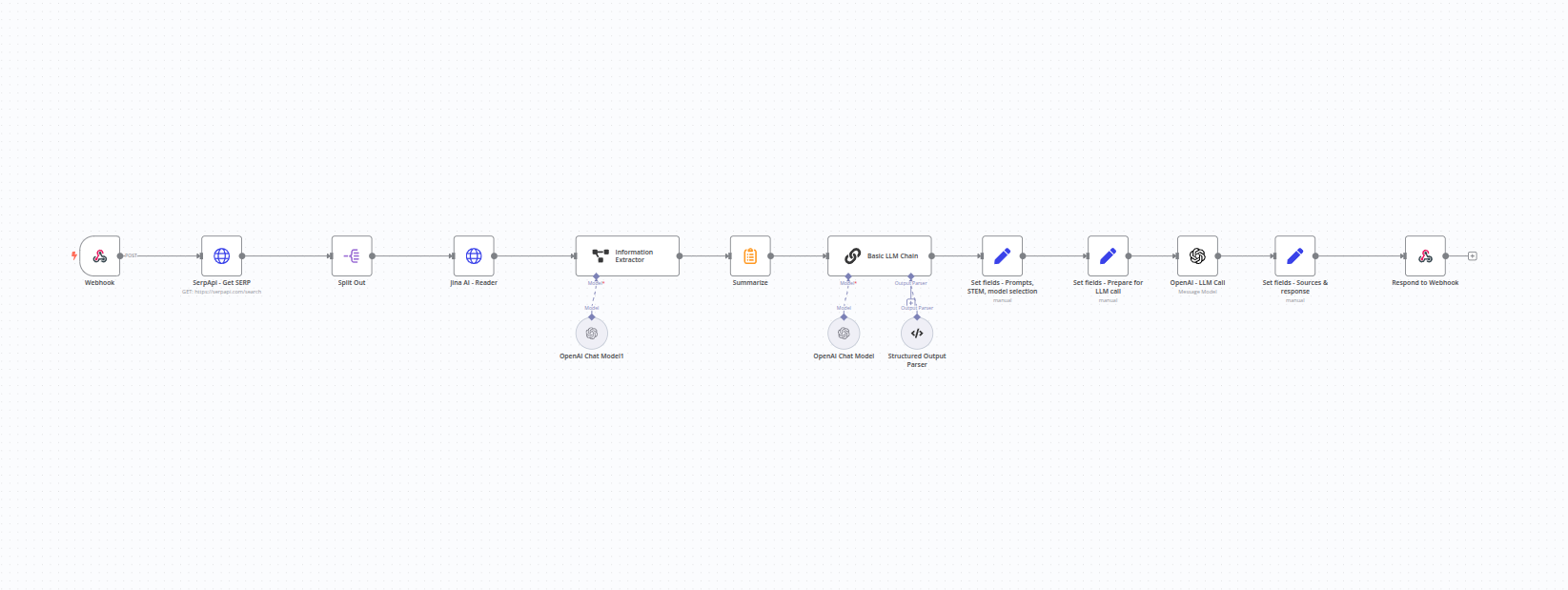
L’app aurait pu être codée entièrement par le modèle o1. Mais :
- faire développer du code que l’on ne comprend pas entièrement est à éviter
- le backend, totalement décorrélé de Streamlit, pourra être utilisé avec un autre frontend
- n8n intègre Langchain, facilite les logiques conditionnelles, permet d’utiliser des webhook pour fonctionner presque comme une API… c’est parfait !
Tu trouveras dans cette partie tous les nodes utilisés dans le workflow n8n.
Node 1 – Webhook Trigger
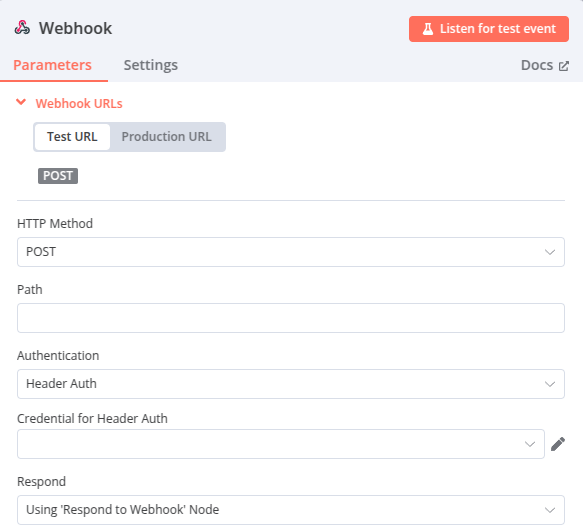
C’est le node qui démarre le workflow ! Il est appelé lorsque l’utilisateur clique sur « Search » dans l’application Streamlit :
Des données sont envoyées grâce à une requête POST.
Le webhook est configuré avec une authentification HTTP. La sécurité pourrait être renforcé avec une Whitelist d’IP.
La réponse est configurée avec un node « Respond to Webhook » : c’est ce node, en fin de workflow, qui retourne la réponse.
Node 2 – HTTP Request – SerpApi
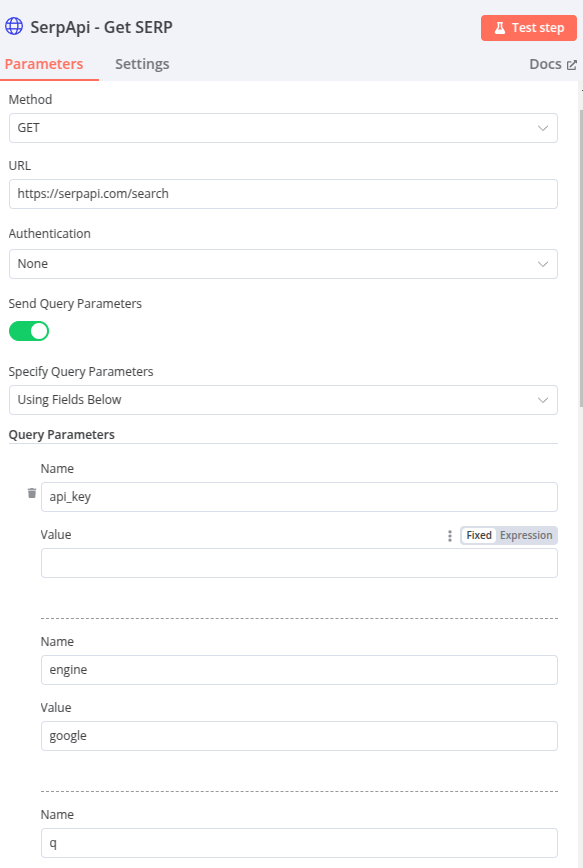
Le deuxième node envoie requête HTTP à SerpApi pour obtenir les résultats google à la question posée sur Streamlit.
Les paramètres s’adaptent dynamiquement en fonction des choix de l’utilisateur sur l’interface Streamlit :
- q : correspond à query, c’est la requête (mot-clé/question) de l’utilisateur
- google_domain : le domaine google (google.com, google.fr…)
- gl : la localisation (le pays)
- hl : la langue utilisée pour la recherche
- device : l’appareil utilisé par SerpApi pour obtenir la SERP (utilité limitée pour cette app)
- num : le nombre de résultats retournés par SERP. Plus de résultats = plus de sources pour générer la réponse (10 par défaut)
Node 3 – Split Out
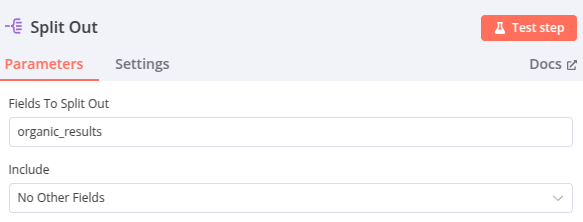
La propriétée organic_results de l’objet JSON retourné par SerpApi est « split » (divisée) pour obtenir une liste de liens faciles à utiliser dans le node suivant.
Node 4 – HTTP Request – JinaAI Reader API
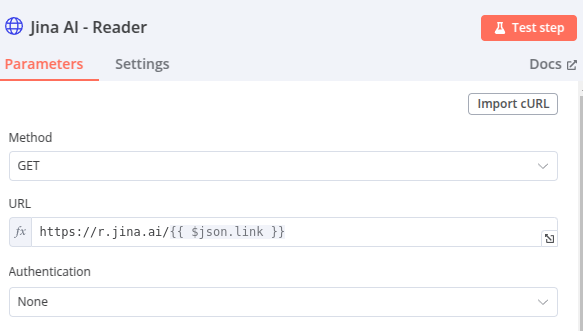
Les liens en sortie du node « Split Out » sont envoyés à Reader API de JinaAI. La sortie est le contenu de ces pages au format Markdown.
Node 5 – Information Extractor
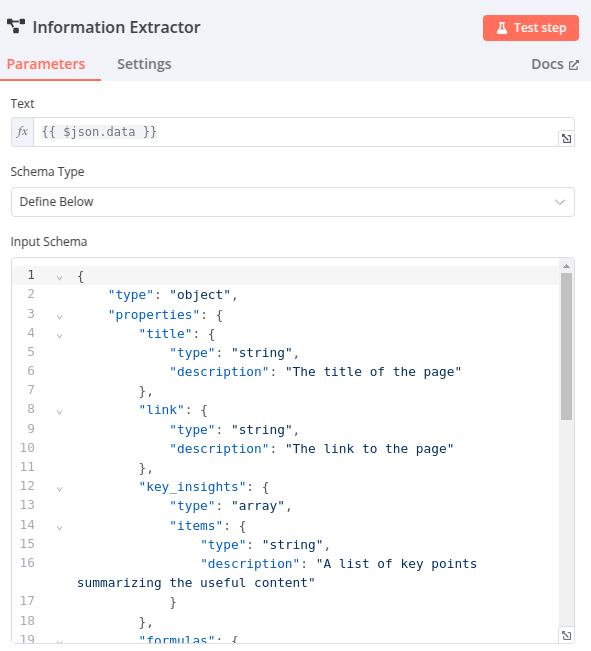
Utilisation d’un LLM pour extraire les informations d’un contenu. En précisant les éléments à rechercher et une description, il génère un JSON structuré selon la configuration du node.
Pour cette app, voici le paramétrage :
Titre (title) :
- Type : Chaîne de caractères
- Description : Le titre de la page
Lien (link) :
- Type : Chaîne de caractères
- Description : Le lien vers la page
Points clés (key_insights) :
- Type : Liste de chaînes de caractères
- Description : Une liste de points clés résumant le contenu utile
Formules (formulas) (optionnel, utile dans le cas de requêtes STEM – Science, Technology, Engineering, and Mathematics,) :
- Type : Liste de chaînes de caractères
- Description : Une liste de formules mathématiques ou scientifiques (au format LaTeX)
Tableaux (tables) (optionnel) :
- Type : Liste de chaînes de caractères
- Description : Une liste de tableaux de données structurées en format Markdown
Extraits de code (code_snippets) (optionnel, utile dans le cas de requêtes STEM) :
- Type : Liste de chaînes de caractères
- Description : Une liste d’extraits de code pertinents extraits de la page (uniquement si nécessaire)
Sub-node : OpenAI ChatModel – gpt-4o-mini
Le modèle de langue utilisée pour extraire les informations. J’ai choisi gpt-4o-mini, mais les tests ont révélé que gpt-3.5-turbo était plus rapide pour cette tâche.
Node 6 – Summarize – Aggrégation
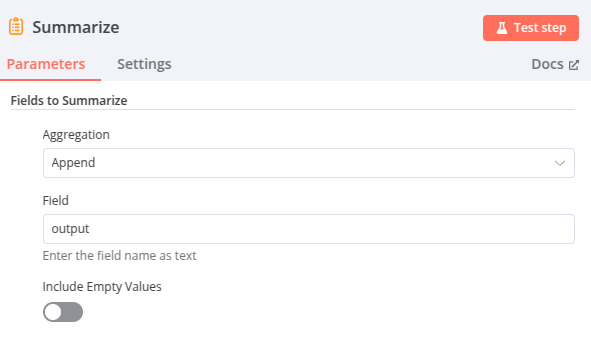
Ce node aggrège les résultats obtenus précédemment : Ils seront envoyés en un bloc au LLM de l’étape 10 qui sert à générer la réponse.
Node 7 – Basic LLM Chain – STEM?
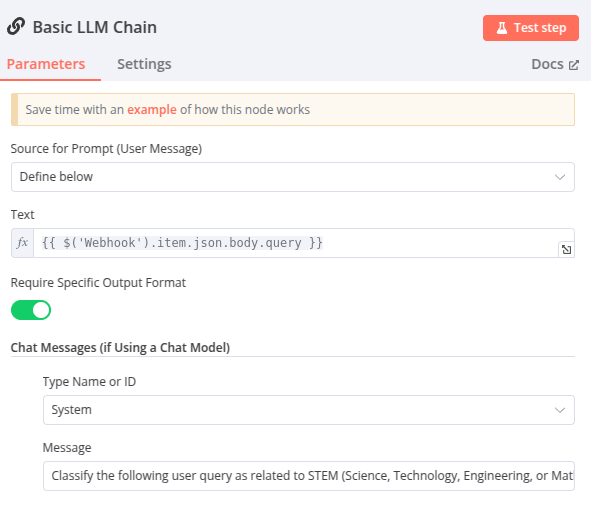
Ce node classifie si une requête porte sur un sujet « STEM » ou non.
Sa sortie (true ou false) sera ensuite utilisée dans le workflow pour définir une logique conditionnelle et choisir le modèle de langue approprié.
Pour une question STEM, les modèles o1 ou o1-mini sont à privilégier, car ils excellent dans ce type de requêtes. Le prompt est également adapté en fonction du sujet (STEM ou non de) la question.
Dans ce workflow, ce node est placé à l'étape 7, car les étapes précédentes ne dépendent pas du fait que la requête soit sur un sujet STEM ou non. Mais son emplacement peut varier !
Par exemple, il pourrait être placé plus tôt pour adapter un prompt en fonction du sujet (STEM ou non) de la question dès l'étape 5 – Information Extractor.
Dans ce cas, le node 'Basic LLM Chain - STEM?' interviendrait plus tôt dans le workflow.
Sub-node : OpenAI ChatModel – gpt-4o-mini
Le modèle de langue utilisé pour analyser la question de l’utilisateur et la classifier.
Sub-node : Structured Output Parser
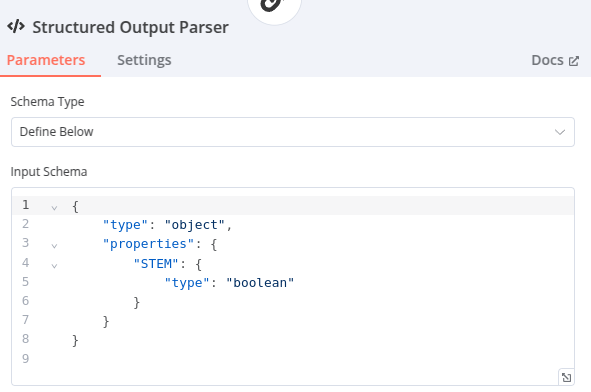
La structure de sortie attendue. Il s’agit d’un objet JSON contenant une propriété STEM de type booléen (true ou false).
Node 8 – Set fields : Prompts, STEM, Model selection
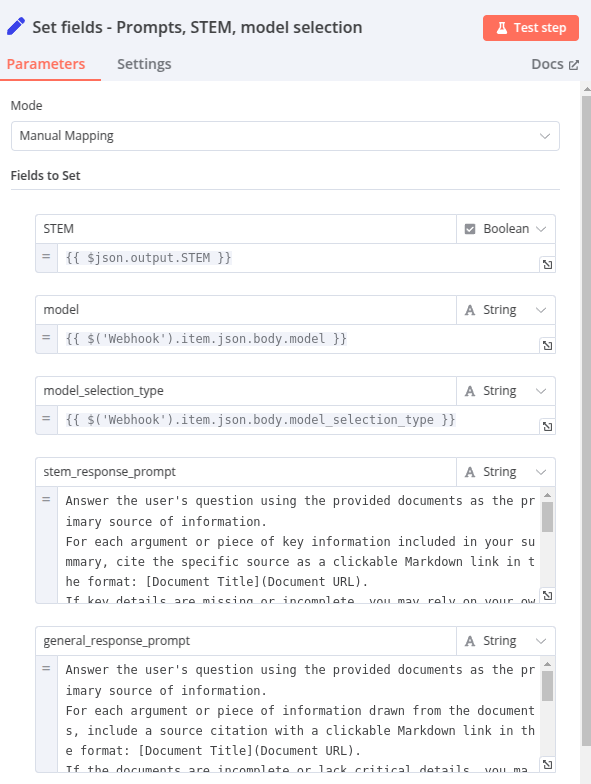
Ce node définit les champs qui seront qui seront utilisés dans une logique conditionnelle à l’étape suivante.
- STEM : la sortie du Node 7 – Basic LLM Chain – STEM? donc, la valeur est « true » ou « false »
- model : le modèle sélectionné par l’utilisateur
- model_selection_type : prend la valeur « auto » ou « manual »
- stem_response_prompt : Le prompt qui sera utilisé pour générer une réponse à la question de l’utilisateur si elle porte sur un sujet STEM.
- general_response_prompt : Le prompt qui sera utilisé pour générer une réponse à la question de l’utilisateur si elle porte sur tout autre sujet que STEM.
Node 9 Set fields – Prepare for LLM Call
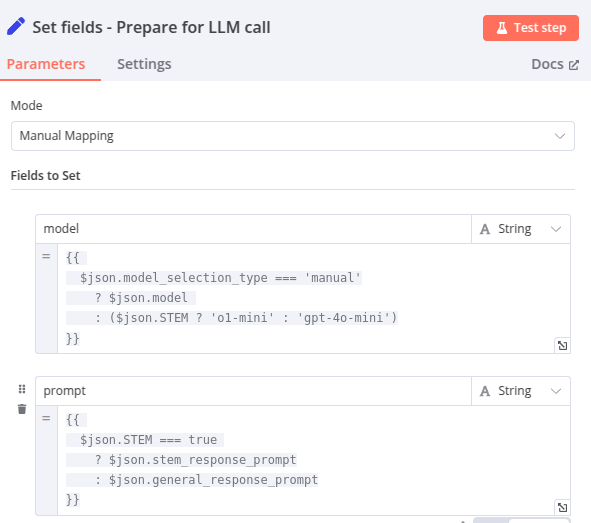
Ce node paramètre les champs « model » et « prompt » (qui seront utilisés pour le « LLM call ») avec des logiques conditionnelles :
- model : Si la propriété
model_selection_typedu JSON (sortie de l’étape précédente) est égale à'manual', alors la valeur demodelest utilisée. Sinon, si la propriétéSTEMesttrue, le modèle sélectionné est'o1-mini', et s’il estfalse, le modèle sélectionné est'gpt-4o-mini'(dans le cas ou c’est « auto » c’est toujours le modèle avec le meilleur rapport coût-performance qui est choisi) - prompt : Si la propriété
STEMdu JSON (sortie de l’étape précédente) esttrue, alors la valeur destem_response_promptest utilisée. Sinon, la valeur degeneral_response_promptest sélectionnée.
Ainsi, le modèle et prompt utilisés dans l’étape suivante sont optimisés selon le type de question et les paramétrages de l’utilisateur.
Node 10 – OpenAI – LLM Call
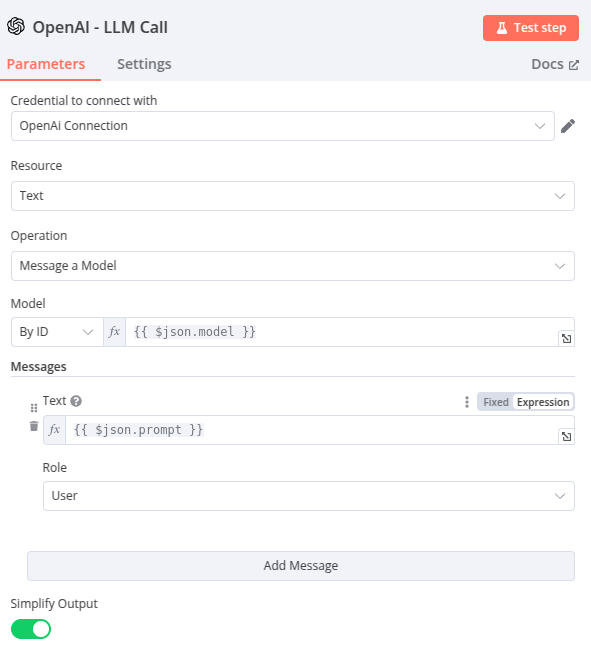
Un appel API à OpenAI, avec :
- model : la sortie « model » du node précédent
- prompt: « la sortie « prompt » du node précédent
- Simplify Output :
true, la sortie JSON (réponse de l’API OpenAI) est simplifiée
Node 11 – Set fields : Sources & Response
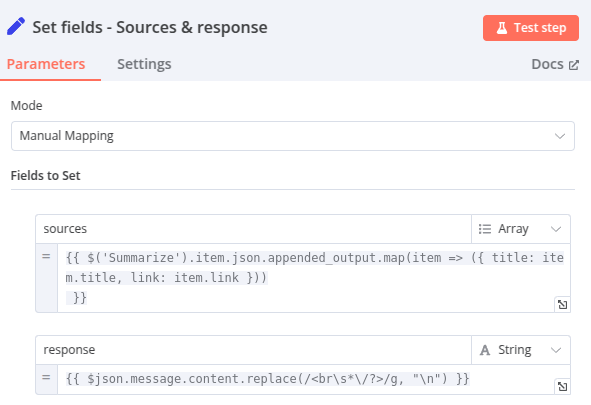
C’est le paramétrage des champs qui seront envoyés en réponse au webhook !
Il y en a 2 :
- sources : les titres et liens des contenus qui ont servi de documents pour générer la réponse. Ils sont récupérés depuis le Node 6 – Summarize – Aggrégation
- response : la réponse à la requête de l’utilisateur
Node 12 – Respond to Webhook
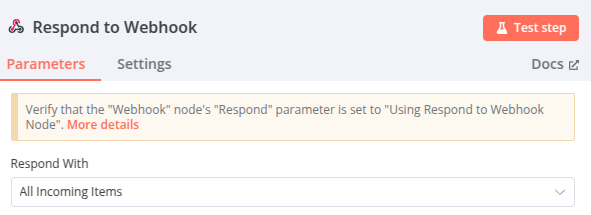
La réponse retournée au webhook ! Paramétré avec « All Incoming Items ». Les deux champs « sources » et « response » paramétrés lors du node précédent sont retournés.
Résultats et limites
Qualité des réponses
Les réponses sont précises, utilisent correctement les sources et le format Markdown améliore la lecture. C’est très utile pour afficher des tableaux et du code, par exemple.
Bien sûr, cela dépend du modèle ! L’utilisateur peut poser une question sur un sujet STEM, et choisir gpt-4o-mini, donc la réponse sera moins pertinente que s’il avait choisi « auto » ou o1/o1-mini.
Limites
Contrairement à Perplexity qui est rapide, il y a une dizaine de secondes entre le clique sur « Search » et l’affichage des résultats. C’est l’étape « information extractor » qui prend du temps.
J’ai essayé avec gemini 2.0-flash qui est un modèle plus rapide que gpt-4o-mini (en output tokens par secondes) : la réponse est retournée plus vite, mais, pour certaines requêtes, je trouvais l’extraction d’informations moins qualitative.
Les réponses se basent uniquement sur les sources provenant du moteur de recherche Google. Disons que c’est une app qui « synthétise les réponses des résultats google » plutôt qu’un réel Perplexity. Plusieurs améliorations peuvent être apportées :
- utilisation d’autres moteurs de recherche
- possibilité pour l’utilisateur d’inclure/exclure des domaines comme sources
- ajout du conversationnel, pour que l’utilisateur puisse discuter avec l’IA, comme sur Perplexity
- ajout d’autres sources que des contenus texte (vidéos, images…)
- le « num » en paramètre de l’appel API à SerpApi retourne, selon la SERP, moins de résultats que demandé. Par exemple, 10, peut ne retourner que 7 liens qui serviront de sources. Le workflow n8n peut-être modifié : demander la SERP complète (~100 résultats) et ajouter un node « limit » qui lui, dépendra du choix de l’utilisateur
Tu veux essayer ? Tout est sur github
Si tu veux essayer, tu peux retrouver tous les fichiers dans ce repo github :